Introduction
Video understanding is central to real-world applications such as autonomous driving, online tutorial development, assistive robotics, and movie analysis. Despite recent advances in vision-language models (VLMs), performance has lagged behind text-based reasoning, especially for tasks involving long-context video understanding.
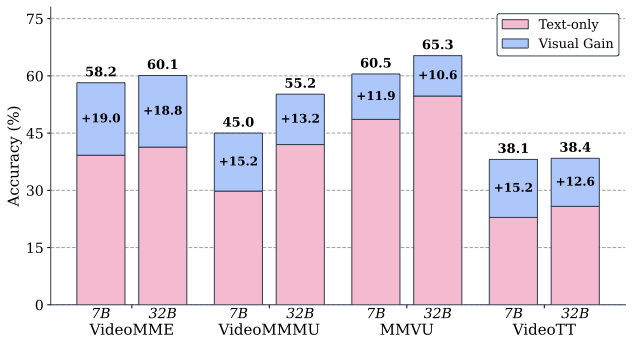
In this work, we show that the community’s progress in improving video understanding in VLMs is even worse than initially thought, with a majority of the gains coming from models’ abilities to answer questions without access to the video.
This phenomenon, known as “linguistic short-cutting” has been well established in Vision Question Answering (VQA) as a serious problem. We find that most video gains come from being able to answer a larger portion of the benchmark without access to the video, making these benchmarks problematic for measuring improvements in genuine video understanding.
Key Contributions
- Identifying Linguistic Shortcutting: We identify the pervasive presence of linguistic shortcutting in both video understanding benchmarks (30-50% text-only answerable) and post-training datasets
- VidFilter: We introduce VidFilter, an exceedingly simple method for improving VLM post-training: simply filtering out text-only answerable questions
- Data Efficiency: Although this strategy filters out approximately 30% of the post-training data, it leads to improvements of 2.5-3% in video understanding performance
- Outperforming Complex Methods: This simple approach outperforms several more advanced post-training strategies such as stronger fusion modules, debiasing objectives, or RL-based post-training
Method
Guided by our analyses, we introduce VidFilter, a simple technique for improving video understanding in VLMs through post-training. VidFilter combines reinforcement learning techniques for post-training with a simple data filter.
RL for Video Understanding Post-Training
We use reinforcement learning (RL) for post-training based on recent evidence that RL improves underlying visual recognition capabilities while exhibiting less catastrophic forgetting than supervised fine-tuning (SFT).
We adopt Group Relative Policy Optimization (GRPO) augmented with techniques from DAPO and temporal-aware rewards from Video-R1. Specifically, we employ token-level policy gradient loss with asymmetric clipping to make the training more efficient and stable.
Post-Training Data Filter
We construct our post-training data based on Video-R1-260k, which comprises 116,248 Video QA and 146,823 Image QA instances spanning diverse video and image understanding scenarios.
We partition Video-R1-260k into three variants based on text answerability:
| Variant | Samples | TA Ratio | Description |
|---|---|---|---|
| Full | 263,071 | 30.9% | Common post-training practice without filtering |
| TA | 81,361 | 100% | Only text-only answerable questions |
| NTA (VidFilter) | 181,710 | 0% | Only video-dependent questions |
Experiments
We evaluate on four video understanding benchmarks:
- VideoMME: A comprehensive, general-purpose benchmark spanning perception and reasoning
- VideoMMMU: Focused on expert-level, multi-disciplinary video reasoning
- MMVU: Emphasizing college-level, knowledge-intensive video comprehension
- VideoTT: Assessing understanding of visual narratives
Main Results
| Method | VideoMME | VideoMMMU | MMVU | VideoTT | Avg |
|---|---|---|---|---|---|
| Qwen2.5-VL-7B | 48.5 | 36.2 | 47.0 | 36.4 | 42.0 |
| Video-R1 | 48.9 | 36.4 | 43.8 | 38.0 | 41.8 |
| LongVILA-R1-7B | 50.9 | 30.9 | 46.9 | 41.7 | 42.6 |
| LLaVA-Critic-R1 | 50.2 | 37.1 | 49.9 | 34.8 | 43.0 |
| VidFilter (Ours) | 51.8 | 39.5 | 51.4 | 37.9 | 45.2 |
Key Findings
Less is More: VidFilter, post-trained on 182K NTA samples, consistently outperforms models trained on the full 263K dataset, using only 69.1% of the post-training data.
Consistent Frame Scaling: Models trained on NTA data show steady improvement as the number of frames increases, while models trained on full data exhibit inconsistent scaling and minimal gains.
Qualitative Results

Conclusion
We identify the pervasive presence of linguistic shortcutting in both video understanding benchmarks and post-training datasets. Some of the most popular video understanding benchmarks are at least 50% composed of questions which can be answered using the question text alone.
We developed VidFilter, an exceedingly simple post-training strategy for improving video understanding: filtering out text-only answerable questions from the post-training dataset. This strategy outperforms seven state-of-the-art approaches while providing notable benefits in training data efficiency.
Our findings highlight the importance of curating post-training data that truly requires visual reasoning, offering a simple yet powerful direction for building more robust and visually grounded VLMs.
Additional Materials
Code and Data
Code and datasets will be released upon publication.